
AI经典论文综述
1.Distilling the Knowledge in a Neural Network
主要工作(What)
- “蒸馏”(distillation):把大网络的知识压缩成小网络的一种方法
- “专用模型”(specialist models):对于一个大网络,可以训练多个专用网络来提升大网络的模型表现
具体做法(How)
- 蒸馏:先训练好一个大网络,在最后的softmax层使用合适的温度参数T,最后训练得到的概率称为“软目标”。以这个软目标和真实标签作为目标,去训练一个比较小的网络,训练的时候也使用在大模型中确定的温度参数T
- 专用模型:对于一个已经训练好的大网络,可以训练一系列的专用模型,每个专用模型只训练一部分专用的类以及一个“不属于这些专用类的其它类”,比如专用模型1训练的类包括“显示器”,“鼠标”,“键盘”,…,“其它”;专用模型2训练的类包括“玻璃杯”,“保温杯”,“塑料杯”,“其它“。最后以专用模型和大网络的预测输出作为目标,训练一个最终的网络来拟合这个目标。
意义(Why)
蒸馏把大网络压成小网络,这样就可以先在训练阶段花费大精力训练一个大网络,然后在部署阶段以较小的计算代价来产生一个较小的网络,同时保持一定的网络预测表现。
对于一个已经训练好的大网络,如果要去做集成的话计算开销是很大的,可以在这个基础上训练一系列专用模型,因为这些模型通常比较小,所以训练会快很多,而且有了这些专用模型的输出可以得到一个软目标,实验证明使用软目标训练可以减小过拟合。最后根据这个大网络和一系列专用模型的输出作为目标,训练一个最终的网络,可以得到不错的表现,而且不需要对大网络做大量的集成计算。

2.Deep Neural Networks are Easily Fooled:High Confidence Predictions for Unrecognizable Images
首次提出假反例攻击,即:生成人类无法识别的图片,却能够让神经网络以高置信度分类成某个类别
使用了多种不同的方法生成图片,称为“fooling images”
- 普通的EA算法(进化算法),对图片的某个像素进行变异、进化
- CPPN EA算法,可以为图像提供一些几何特性,如对称等
- 梯度上升:计算DNN的softmax的输出对于输入的梯度,我们根据梯度来增加一个单元的激活值,目的是去找到一个图片能够得到很高的分类置信度。
介绍了在MNIST数据集和ImageNet数据集上进行实验的区别
在MNIST数据集上,由于数据量小,得到的网络模型的容量小,更容易生成fooling images,也更难通过利用fooling images重新训练模型的方式 来提高其防御能力
在ImageNet数据集上,数据量大,类别多,得到的网络模型的容量大,更难生成fooling images,不过由于其容量大,能够通过重新训练的方式提高防御能力
灰度 : MNIST
深度神经网络: DNN
CPPN:合成模式生成网络:compositional pattern-producing network
3.How transferable are features in deep neural networks?
小结论:前面几层都学习到的是通用的特征(general feature),随着网络的加深,后面的网络更偏重于学习特定的特征
问题:我们怎么知道哪些层是general/specific?更进一步:如果应用于迁移学习,如何决定该迁移哪些层固定哪些层?
答:围绕着神经网络的可迁移性,作者设计了两大方面的实验:
- 迁移A网络的某n层到B(AnB) vs 固定B网络的某n层(BnB)
- 权重初始化与迁移表现
AnB:(所有实验都是针对数据B来说的)将A网络的前n层拿来并将它frozen,剩下的8-n层随机初始化,然后对B进行分类。
BnB:把训练好的B网络的前n层拿来并将它frozen,剩下的8-n层随机初始化,然后对B进行分类。
随着可迁移层数的增加,模型性能下降。但是,前3层仍然还是可以迁移的,同时,与随机初始化所有权重比较,迁移学习的精度是很高的
结论:
- 神经网络的前3层基本都是general feature,进行迁移的效果会比较好;
- 深度迁移网络中加入fine-tune(微调),效果会提升比较大,可能会比原网络效果还好;
- Fine-tune可以比较好地克服数据之间的差异性;
- 深度迁移网络要比随机初始化权重效果好;
- 网络层数的迁移可以加速网络的学习和优化。
4.CNN Features off-the-shelf: an Astounding Baseline for Recognition
结论:CNN通过深度学习获得的特征应该是大多数视觉识别任务的主要选择
5.Oquab_Learning_and_Transferring_2014_CVPR_paper
结论:论文揭露了在大规模数据集(ImageNet dataset)上训练的神经网络,可以高效地迁移到其他小数据集(PASCAL VOC 2007/2012 dataset)上。论文通过对PASCAL VOC图片进行sliding处理,解决了两个数据集之间存在的”dataset label bias”问题。论文提供了一种简单有效的迁移方法,并对迁移结果进行了实验考察。结果表明,使用迁移的特征比重新训练往往能获得更好的表现
6.Visualizing and Understanding Convolutional Networks
简单介绍(What)
- 提出了一种可视化的技巧,能够看到CNN中间层的特征功能和分类操作。
- 通过对这些可视化信息进行分析,我们可以
- 直观了解和分析CNN学到的特征(中间层特征对应什么样的图像)
- 可以找到提升模型的办法(观察中间层特征,分析模型可以改进的地方)
- 分析CNN的遮掩敏感性(遮住某一块区域后对分类结果的影响)
- 这种可视化技巧主要用到反卷积的技术,把中间层的激活特征映射回输入空间。
论文动机(Why)
- 虽然CNN在图像任务上取得了优秀的表现,但是看不到CNN的内部操作和复杂模型的表现行为,不清楚它们为何会取得这么好的效果。
- 在科学的角度上,这是不能接收的,没有清晰地理解CNN是如何工作以及为什么这样运作,那么它的发展和进步就只能靠不断地“试错”。
- 所以论文提出了可视化的技巧,可以观察到训练过程中特征的演化和影响,可以分析模型潜在的问题。
怎么做的(How)
- 论文的网络结构和alexNet很类似,做了一些改动,比如stride变成2,11x11的卷积核变成7x7的卷积核。
- 为了把中间层的激活块映射回输入空间,使用了反卷积的技术,如下图所示,右边是卷积网,左边是反卷积网。
- 反池化:由于池化操作不可逆,使用了一个近似可逆的方法,用Switches记录每个池化块最大值的位置,如下图所示,这样就可以利用Switches和池化后的特征图,反池化成Unpooled Maps
- relu:反池化后,为了获得有效的特征重建,也使用relu,得到Rectified Unpooled Maps
- 反卷积:用原来卷积核的转置版本,进行卷积操作,得到重建的Reconstruction
总结
- 提出了一种可视化CNN的方法,说明了内部特征并不是随机的,是可以解释的。
- 通过可视化CNN了解到了一些直觉上的特性,比如随着增加层数,类别的可区分度越高,特征越有用。
- 通过可视化CNN可以对模型进行分析和改善。
- 通过可视化CNN的遮蔽实验,发现模型对局部结构是敏感的,并不是只用到了广阔的场景信息。
- 展示了ImageNet的预训练模型可以很好地泛化到其它数据集。
7.Training Very Deep Networks - Highway Networks
目标:怎么训练很深的神经网络
然而过深的神经网络会造成各种问题,梯度消失之类的,导致很难训练,作者利用了类似LSTM的方法,通过增加gate来控制transform前和transform后的数据的比例,称为 Highway network
论文贡献:
文章提出了Hightway network,基于门机制引入了transform gate T(x.WT)和carry gate C(x,WT),使得训练更深的网络变为可能,并且加快了网络的收敛速度。
论文思想基础:
1.在前馈网络结构中传统非线性变换的叠加会导致激活和梯度的传播不良。
2.采用两个门transform gate 和 carry gate 来控制当前层的输出形式,输出形式来自两部分:当前层的直接输入和经过非线性映射后的部分。
8.Delving Deep into Rectifiers:Surpassing Human-Level Performance on ImageNet Classification
核心内容就两个方面,首先提出PReLU激活函数,接着提出一种鲁棒性的权重初始化的方法。同时也宣告深度学习特定图像集合的识别率超越人类水平。
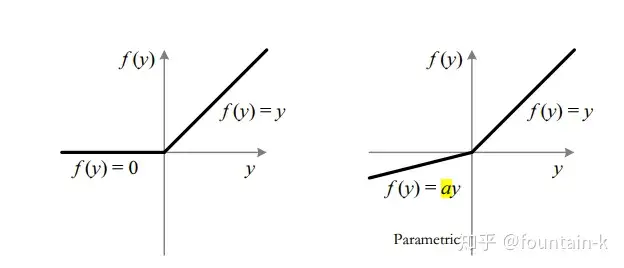
ReLU vs PReLU