
AI笔记(1):基础知识
基本名词
- 示例/样本:上面一条数据集中的一条数据。
- 属性/特征:「色泽」「根蒂」等。
- 属性空间/样本空间/输入空间X:由全部属性张成的空间。
- 特征向量:空间中每个点对应的一个坐标向量。
- 标记:关于示例结果的信息,如((色泽=青绿,根蒂=蜷缩,敲声=浊响),好瓜),其中「好瓜」称为标记。
- 分类:若要预测的是离散值,如「好瓜」,「坏瓜」,此类学习任务称为分类。
- 假设:学得模型对应了关于数据的某种潜在规律。
- 真相:潜在规律自身。
- 学习过程:是为了找出或逼近真相。
- 泛化能力:学得模型适用于新样本的能力。一般来说,训练样本越大,越有可能通过学习来获得具有强泛化能力的模型。
欠拟合(Underfitting):常常在模型学习能力较弱,而数据复杂度较高的情况出现,此时模型由于学习能力不足,无法学习到数据集中的“一般规律”,因而导致泛化能力弱。
过拟合(Overfitting):模型学习能力太强,以至于将训练集单个样本自身的特点都能捕捉到,并将其认为是“一般规律”,同样这种情况也会导致模型泛化能力下降。
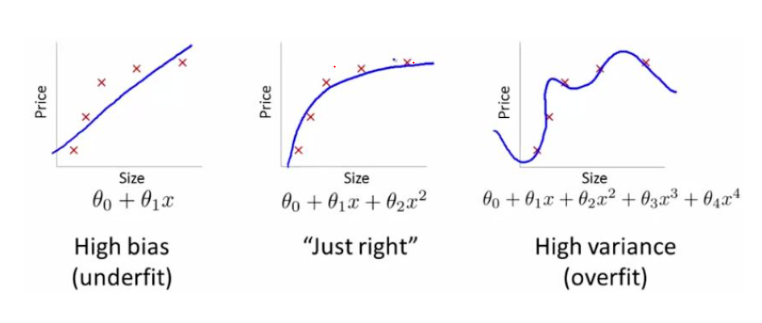
偏差 (Bias) 和方差 (Variance) 是机器学习领域非常重要的两个概念和需要解决的问题。在传统的机器学习算法中,Bias和Variance是对立的,分别对应着欠拟合和过拟合.
偏差(Bias):度量了学习算法的期望预测与真实结果的偏离程度,即刻画了学习算法本身的拟合能力
方差(Variance):度量了同样大小的训练集的变动所导致的学习性能的变化,即刻画了数据扰动所造成的影响。
High Bias对应着欠拟合,而High Variance对应着过拟合。在欠拟合 (underfitting) 的情况下,出现高偏差 (High Bias) 的情况,即不能很好地对数据进行分类.
- 训练集的错误率较小,而验证集的错误率却较大,说明模型存在较大方差 (Variance) ,可能出现了过拟合。
- 训练集和验证集的错误率都较大,且两者相当,说明模型存在较大偏差 (Bias) ,可能出现了欠拟合。
- 训练集错误率较大,且验证集的错误率远较训练集大,说明方差和偏差都较大,模型很差。
- 训练集和验证集的错误率都较小,且两者的相差也较小,说明方差和偏差都较小,这个模型效果比较好。
模型存在高偏差:扩大网络规模,如添加隐藏层或隐藏单元数目;寻找合适的网络架构,使用更大的NN结构;花费更长时间训练。模型存在高方差:获取更多的数据;正则化 (Regularization) ;寻找更合适的网络结构。
正则化: 若参数过多,模型过于复杂,则会容易造成过拟合(overfitting)。即模型在训练样本数据上表现的很好,但在实际测试样本上表现的较差,不具备良好的泛化能力。 为了避免过拟合,最常用的一种方法是使用正则化,例如 L1 和 L2 正则化。
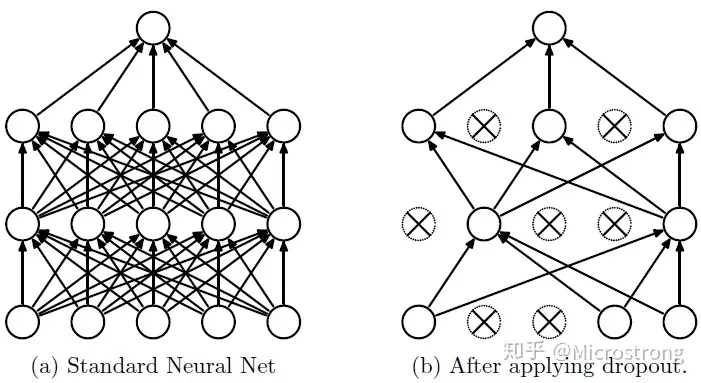
Dropout:解决过拟合问题,我们在前向传播的时候,让某个神经元的激活值以一定的概率p停止工作,这样可以使模型泛化性更强,因为它不会太依赖某些局部的特征,如图:
分类问题
分类问题是机器学习非常重要的一个组成部分。它的目标是根据已知样本的某些特征,判断一个新的样本属于哪种已知的样本类。分类问题可以细分如下:
- 二分类问题:表示分类任务中有两个类别新的样本属于哪种已知的样本类。
- 多类分类(Multiclass classification)问题:表示分类任务中有多类别。
- 多标签分类(Multilabel classification)问题:给每个样本一系列的目标标签。
回归类问题:
监督学习(Supervised Learning):训练集有标记信息,学习方式有分类和回归。从给定的训练数据集中学习出一个函数,当新的数据到来时,可以根据这个函数预测结果。监督学习的训练集要求是包括输入和输出,也可以说是特征和目标。训练集中的目标是由人标注的。常见的监督学习算法包括回归分析和统计分类
无监督学习(Unsupervised Learning):训练集没有标记信息,学习方式有聚类和降维。与监督学习相比,训练集没有人为标注的结果。常见的无监督学习算法有生成对抗网络(GAN)、聚类。
强化学习(Reinforcement Learning):有延迟和稀疏的反馈标签的学习方式。通过观察来学习做成如何的动作。每个动作都会对环境有所影响,学习对象根据观察到的周围环境的反馈来做出判断。
损失函数:用于量化衡量预测结果与真实值之间的差距,我们会通过优化损失函数来不断调整模型权重,使其最好地拟合样本数据。均方差损失(MSE):
代价函数:是定义在整个训练集上的,是所有样本误差的平均,也就是损失函数的平均。=成本函数
成本函数:为全体训练样本上的表现,即 个样本的损失函数的平均值,反映了
个样本的预测输出与真实样本输出
的平均接近程度
激活函数:是一种添加到人工神经网络中的函数,旨在帮助网络学习数据中的复杂模式。类似于人类大脑中基于神经元的模型,激活函数最终决定了要发射给下一个神经元的内容。
训练集:用来训练模型内参数的数据集
验证集:用于在训练过程中检验模型的状态,收敛情况。验证集通常用于调整超参数,根据几组模型验证集上的表现决定哪组超参数拥有最好的性能。同时验证集在训练过程中还可以用来监控模型是否发生过拟合
测试集:用来评价模型泛化能力,即之前模型使用验证集确定了超参数,使用训练集调整了参数,最后使用一个从没有见过的数据集来判断这个模型是否Work。
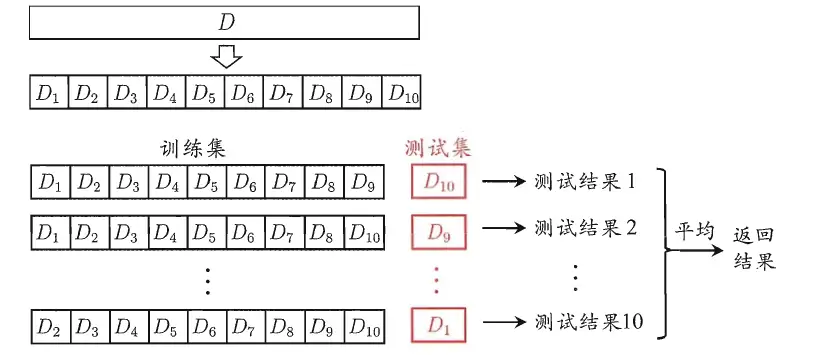
**交叉验证法:**交叉验证法的作用就是尝试利用不同的训练集/测试集划分来对模型做多组不同的训练/测试,来应对单词测试结果过于片面以及训练数据不足的问题。
交叉验证的做法就是将数据集粗略地分为比较均等不相交的k份,即

然后取其中的一份进行测试,另外的k-1份进行训练,然后求得error的平均值作为最终的评价,具体算法流程西瓜书中的插图如下:
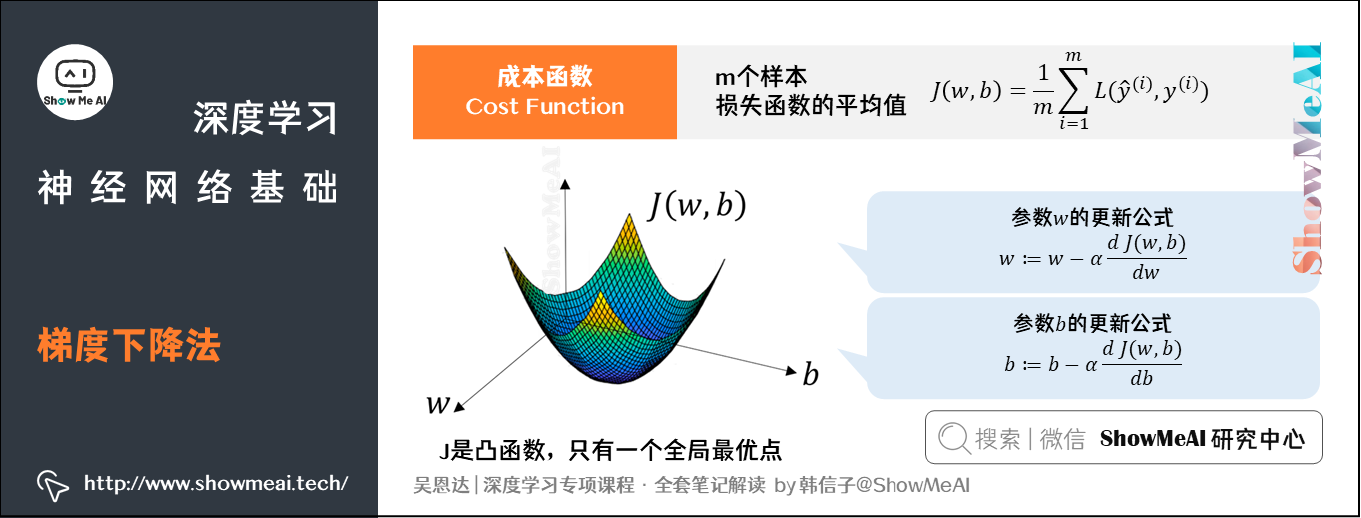
梯度下降:我们就要找到最优的 和
值,最小化
个训练样本的Cost Function。这里用到的方法就叫做梯度下降(Gradient Descent)算法。
模型的训练目标是寻找合适的 与
以最小化代价函数值。我们先假设
与
都是一维实数,则代价函数
关于
与
的图如下所示:
前向传播: 将上一层的输出作为下一层的输入,并计算下一层的输出,一直到运算到输出层为止。
反向传播:反向传播是一种与最优化方法(如梯度下降法)结合使用的,该方法对网络中所有权重计算损失函数的梯度。根据微积分中的链式规则,按相反的顺序从输出层到输入层遍历网络。 这个梯度会反馈给最优化方法,用来更新权值以最小化损失函数。
步骤:求损失函数最小值 → 梯度下降法 → 求梯度 → 求偏导数
前向传播是为反向传播准备好要用到的数值,反向传播本质上是一种求梯度的高效方法。
TP True Positive,预测结果为正类,且与事实相符,即事实为正类。
TN True Negative,预测结果为负类,且与事实相符,即事实为负类。
FP False Positive,预测结果为正类,但与事实不符,即事实为负类。
FN False Negative,预测结果为负类,但与事实不符,即事实为正类。
有了结果分类,就可以计算指标了。常见有三个指标:准确率、精确率(查准率)、召回率(查全率)
准确率
从上面的计算式可知,准确率的含义是模型猜对了的结果在全部结果中的占比,猜对的越多,得分就越高。精确率(查准率)
分母说的是所有预测为正类的结果,分子说的是正类结果中猜对了的那部分。换句话说,模型预测对正类结果的预测越准确,查准率就越高。召回率(查全率)
整个表达式的意思是,在全部正类中,看看模型能正确找出来多少,找出来的越多,查全率就越高。
机器学习工作流(WorkFlow)包含数据预处理(Processing)、模型学习(Learning)、模型评估(Evaluation)、新样本预测(Prediction)几个步骤。
- 数据预处理:输入(未处理的数据 + 标签)→处理过程(特征处理+幅度缩放、特征选择、维度约减、采样)→输出(测试集 + 训练集)。
- 模型学习:模型选择、交叉验证、结果评估、超参选择。
- 模型评估:了解模型对于数据集测试的得分。
- 新样本预测:预测测试集。
梯度消失:经常出现,产生的原因有:一是在深层网络中,二是采用了不合适的损失函数,比如sigmoid。当梯度消失发生时,接近于输出层的隐藏层由于其梯度相对正常,所以权值更新时也就相对正常,但是当越靠近输入层时,由于梯度消失现象,会导致靠近输入层的隐藏层权值更新缓慢或者更新停滞。这就导致在训练时,只等价于后面几层的浅层网络的学习。
梯度爆炸:一般出现在深层网络和权值初始化值太大的情况下。在深层神经网络或循环神经网络中,误差的梯度可在更新中累积相乘。如果网络层之间的梯度值大于 1.0,那么重复相乘会导致梯度呈指数级增长,梯度变的非常大,然后导致网络权重的大幅更新,并因此使网络变得不稳定。
如果接近输出层的激活函数求导后梯度值大于1,那么层数增多的时候,最终求出的梯度很容易指数级增长,就会产生梯度爆炸;相反,如果小于1,那么经过链式法则的连乘形式,也会很容易衰减至0,就会产生梯度消失。
梯度爆炸会伴随一些细微的信号,如:①模型不稳定,导致更新过程中的损失出现显著变化;②训练过程中,在极端情况下,权重的值变得非常大,以至于溢出,导致模型损失变成 NaN等等。
神经网络相关知识
神经网络:如果我们有一个𝑛 × 𝑛的图像,用𝑓 × 𝑓的过滤器做卷积,那么输出的维度就是(𝑛 − 𝑓 + 1) × (𝑛 − 𝑓 + 1)。
例:如果你用一个3×3 的过滤器卷积一个6×6 的图像,你最后会得到一个4×4 的输出,也就是一个4×4 矩阵。那是因为你的3×3 过滤器在6×6 矩阵中,只可能有4×4 种可能的位置

填充(padding):前面可以发现,输入图像与卷积核进行卷积后的结果中损失了部分值,输入图像的边缘被“修剪”掉了(边缘处只检测了部分像素点,丢失了图片边界处的众多信息)。这是因为边缘上的像素永远不会位于卷积核中心,而卷积核也没法扩展到边缘区域以外。
这个结果我们是不能接受的,有时我们还希望输入和输出的大小应该保持一致。为解决这个问题,可以在进行卷积操作前,对原矩阵进行边界填充(Padding),也就是在矩阵的边界上填充一些值,以增加矩阵的大小,通常都用“0”来进行填充的。即填充些没用的数据在外边,使得有用的数据处于中心。
(1)valid padding:不进行任何处理,只使用原始图像,不允许卷积核超出原始图像边界
(2)same padding:进行填充,允许卷积核超出原始图像边界,并使得卷积后结果的大小与原来的一致
迁移学习:神经网络可以从一个任务中习得知识,并将这些知识应用到另一个独立的任务中。例如,你训练好一个神经网络,能够识别像猫这样的对象,然后使用那些知识,或者部分习得的知识去帮助您更好地阅读x 射线扫描图,这就是所谓的迁移学习。
CNN(卷积神经网络)
CNN网络一共有5个层级结构:
- 输入层(INPUT)
- 卷积层(CONV)
- 激活层(RELU)
- 池化层(POOL)
- 全连接层 (FC层 输出层)

输入层:输入数据,一般会并入卷积层。
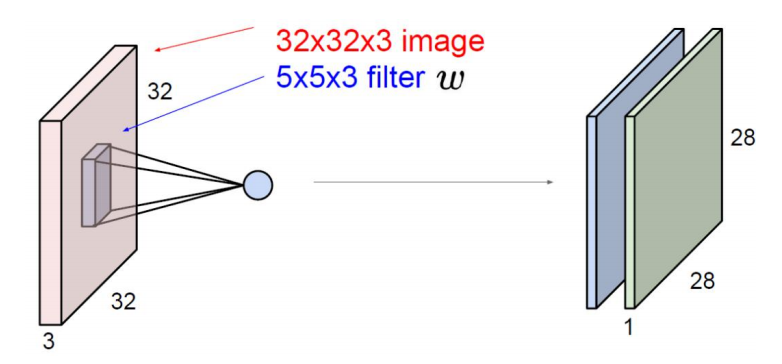
卷积层:如图,卷积层由两个结构组成,x * x * x的图像(三维或二维)和卷积核(滤波器,过滤器),在每一个卷积层中我们都会设置多个核,每个核代表着不同的特征,这些特征就是我们需要传递到下一层的输出,而我们训练的过程就是训练这些不同的核.

激励层:所谓激励,实际上是对卷积层的输出结果做一次非线性映射。 如果不用激励函数(其实 就相当于激励函数是f(x)=x),这种情况下,每一层的输出都是上一层输入的线性函数。容易得出,无论有多少神经网络层,输出都是输入的线性组合,与没有隐层的效果是一样的,这就是最原始的感知机了。
常用的激励函数有:
- Sigmoid函数
- Tanh函数
- ReLU
- Leaky ReLU
- ELU
- Maxout
激励层建议:首先ReLU,因为迭代速度快,但是有可能效果不加。如果ReLU失效的情况下,考虑使用Leaky ReLU或者Maxout,此时一般情况都可以解决。Tanh函数在文本和音频处理有比较好的效果。
池化层:池化层夹在连续的卷积层中间, 用于压缩数据和参数的量,减小过拟合。主要用于特征降维,压缩数据和参数的数量,减小过拟合,同时提高模型的容错性。

主要方式有:
- Max Pooling:最大池化
- Average Pooling:平均池化
Max Pooling:选取最大的,我们定义一个空间邻域(比如,2*2的窗口),并从窗口内的修正特征图中取出最大的元素,最大池化被证明效果更好一些。
Average Pooling:平均的,我们定义一个空间邻域(比如,2*2的窗口),并从窗口内的修正特征图中算出平均值。
全连接层:经过前面若干次卷积+激励+池化后,终于来到了输出层,模型会将学到的一个高质量的特征图片全连接层。其实在全连接层之前,如果神经元数目过大,学习能力强,有可能出现过拟合。因此,可以引入dropout操作,来随机删除神经网络中的部分神经元,来解决此问题。还可以进行局部归一化(LRN)、数据增强等操作,来增加鲁棒性。 
卷积神将网络的计算公式为:N=(W-F+2P)/S+1
其中N:输出大小 W:输入大小 F:卷积核大小 P:填充值的大小 S:步长大小
例:P=1, S=2

白化:白化的目的就是降低输入的冗余性;更正式的说,我们希望通过白化过程使得学习算法的输入具有如下性质:(i)特征之间相关性较低;(ii)所有特征具有相同的方差。
PCA(主成分分析):是一种常见的数据分析方式,常用于高维数据的降维,可用于提取数据的主要特征分量。
循环神经网络(Recurrent Neural Network,RNN):是一种用于处理序列数据的神经网络。相比一般的神经网络来说,他能够处理序列变化的数据。
LSTM - 长短期记忆递归神经网络: 一种特殊的RNN,主要是为了解决长序列训练过程中的梯度消失和梯度爆炸问题。简单来说,就是相比普通的RNN,LSTM能够在更长的序列中有更好的表现。
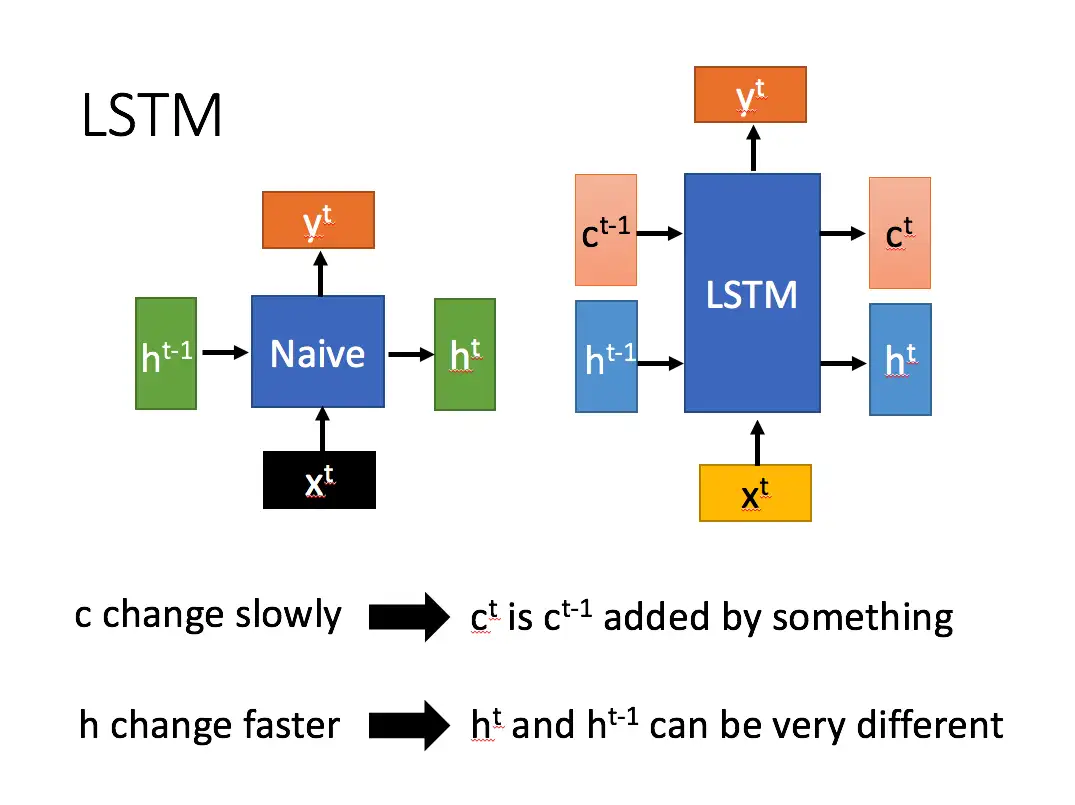

LSTM内部主要有三个阶段:
忘记阶段。这个阶段主要是对上一个节点传进来的输入进行选择性忘记。简单来说就是会 “忘记不重要的,记住重要的”。
选择记忆阶段。这个阶段将这个阶段的输入有选择性地进行“记忆”。主要是会对输入 x^t进行选择记忆。哪些重要则着重记录下来,哪些不重要,则少记一些。当前的输入内容由前面计算得到的 z表示。而选择的门控信号则是由 z^i(i代表information)来进行控制。
这个阶段将决定哪些将会被当成当前状态的输出。主要是通过 z^o来进行控制的。并且还对上一阶段得到的 c^o进行了放缩(通过一个tanh激活函数进行变化)。